-
네이버 카드정보 크롤링, 이제 selenium과 삽질을 곁들인데이터 2025. 3. 23. 16:01
월데노 두 번째 주제로 소비 패턴 파악과 카드 정보를 가지고 필요한 카드 찾기 프로젝트를 진행해보려고 한다. 크롤링을 제대로 해본 경험이 많지는 않아서 쪼끔 걱정이긴했지만 뭐든 일단 해..! 하고 진행해보기로(그리고 시작된 고난의 길)

크롤링을위한 파이썬 라이브러리
크롤링을 하고자할 때, 파이썬에 가장 대표적으로 beautifulSoup과 selenium 두 가지가 있는데요. 저는 이번에 selenium을 활용하여 네이버 신용카드 정보를 크롤링 해보고자 합니다!
beautifulSoup
- HTML, XML 파일을 통해 데이터를 꺼낼 수 있는 라이브러리
- 개인적으로 자주 사용한 함수: find_all(), find(), get_text(), select()
- 참고
selenium
- 프로그램을 이용해 자동화된 웹 테스트를 수행할 수 있도록 해주는 오픈 소스 프레임워크
- 동적 웹 크롤링 가능
- 개인적으로 자주 사용한 함수find_element, find_elements
- 참고
네이버카드정보 크롤링
네이버 신용카드정보 웹 URL: https://card-search.naver.com/list?companyCode=&brandNames=&sortMethod=ri&isRefetch=true&bizType=CPC
네이버 신용카드 정보: 331개 카드 검색결과
331개 카드 검색결과를 확인해 보세요
card-search.naver.com
시작하기 전에
가능하다면 beautifulSoup 만으로 크롤링을 하고싶었으나, 해당 페이지는 동적 웹 페이지로 beautifulSoup만 이용하기에는 한계가 있었습니다. 그래서 selenium까지 함께 사용하여 신용카드 정보 크롤링 작업을 진행했습니다.
📌 필요한 동작: '카드 더보기' 클릭 / '카드 상세 페이지' 접근
*'카드 상세 페이지'의 경우 카드 고유번호(ID)를 이용해 URL 던지는 방식을 채택하여 사실 이 부분은 selenium이 아니어도 괜찮았을 것 같네요..
크게 아래에 작성한 흐름대로 작업 진행했습니다.
1. 네이버 신용카드 정보 URL 접근
2. 필터링 작업
3. 전체 페이지 보기(더보기 클릭)
4. 필요한 데이터 가져오기
필터링, 전체 페이지 보기
신용카드 발급에 있어서 개인적으로 연회비가 3만원 넘어가는 건 필요가 없었기에(혜택을 그만큼 다 챙겨가질 못함) 그리고 실적 금액이 너무 높아도 불편해서 아래 두 가지 조건으로 필터를 먼저 걸어줍니다.(나름의 모수 줄이기😞)
- 필터링(카드 조건)
- 조건: 연회비 3만원 이하
- 월 사용액 50만원 이하
네이버 신용카드 안내 페이지의 경우 '카드 더보기' 탭을 통해 추가 카드 리스트를 보여주는 동적 웹입니다. 따라서 selenium으로 전체 카드리스트를 볼 수 있도록 해줍니다.
url = 'https://card-search.naver.com/list?companyCode=&brandNames=&sortMethod=ri&isRefetch=true&bizType=CPC' driver = webdriver.Chrome(service= Service(ChromeDriverManager().install())) driver.get(url) # 페이지 펼치기(카드 더보기) try: # 연회비 필터 적용 fee_button = driver.find_element(By.CSS_SELECTOR, '#app > div.filters > div > div.category.as_annualFee > div > button:nth-child(3) > span').click() time.sleep(0.4) #전월 실적 금액 필터 적용 amount_per_month = driver.find_element(By.CSS_SELECTOR, '#app > div.filters > div > div.category.as_basePayment > div.list > button:nth-child(3) > span').click() time.sleep(0.4) while True: more_button = driver.find_element(By.CSS_SELECTOR,'#app > div.cards > div > div.tabpanel > button > i').click() time.sleep(0.4) except Exception as e: print("finish")카드 정보 가져오기: 카드 번호(ID), 카드 이름, 설명, 연회비
맥북 기준 command+option+i 키를 눌러 개발자 도구를 열어보면 HTML 소스 코드를 확인할 수 있으며, 우측 Elements 탭에서 필요한 요소에서 여러가지 copy 옵션이 있는 것 또한 확인할 수 있습니다. 저의 경우 필요한 항목인 카드 명(name), 상세 설명(desc), 연회비(annual_fee) 을 차례대로 Copy XPath로 XPath 정보를 가져와 이용합니다.
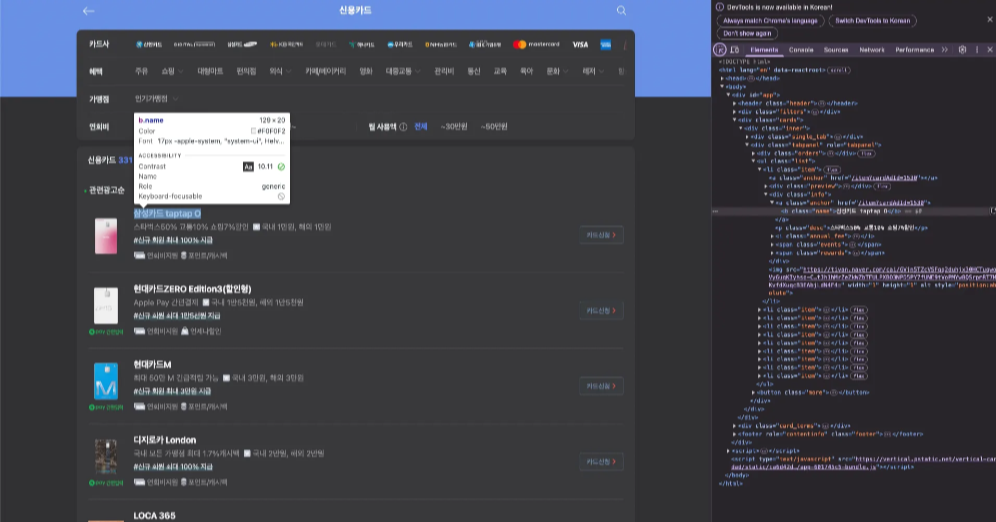

- find_element 활용
- By.XPATH로 li 요소의 번호 변경하며 반복문 전체 데이터를 가져옵니다.
try: i = 1 cards = [] while True: adid_href=driver.find_element(By.XPATH, f'//*[@id="app"]/div[2]/div/div[2]/ul/li[{i}]/div[2]/a').get_attribute('href') adid = re.findall(r'\d+', adid_href) print("adid append success") name=driver.find_element(By.XPATH, f'//*[@id="app"]/div[2]/div/div[2]/ul/li[{i}]/div[2]/a/b') adid.append(name.text) print("name append success") desc=driver.find_element(By.XPATH, f'//*[@id="app"]/div[2]/div/div[2]/ul/li[{i}]/div[2]/p') adid.append(desc.text) print("desc append success") annual_fee=driver.find_element(By.XPATH, f'//*[@id="app"]/div[2]/div/div[2]/ul/li[{i}]/div[2]/i') adid.append(annual_fee.text) print("annual fee append success") cards.append(adid) print("cards append success") i+=1 driver.quit() except Exception as e: print("finish")*find_elemnts를 사용하지 않은 이유: 같은 클래스 name, <b> 태그에 카드 이름 이외 '신용카드' 및 footer 정보와 같은 데이터가 함께 포함되어 추가적인 클렌징 작업이 필요함. 이외에도, 카드 상세 url에 사용을 위한 <a>태그같은 카드 1개의 정보 당 중복으로 존재하는 등의 이슈 ➡️ 개별로 해결이 불가능하진 않지만, find_element로 리스트 순서대로 항목별 데이터를 가져오는 편이 가장 깔끔하고 간단한 방법으로 판단하여 해당 방법으로 진행했습니다.
카드 상세 페이지 혜택 키워드 가져오기
아래 상세 페이지의 '주요혜택' 키워드들을 가져오고자 합니다. 앞서 쌓아둔 카드 고유 번호(ID) 값을 이용해서 상세 페이지 URL을 순회하며 정보를 가져오는 방식으로 진행했습니다. 사실 해당 작업같은 경우는 URL 부분을 변경해서 작업하는 형태로 꼭 selenium으로 작업할 필요는 없었습니다...

*주요혜택의 수는 카드별로 제각각인 관계로 리스트로 들어오는 데이터를 구분자(,)를 기준으로 하나의 문자열로 바꾸어 저장했습니다.
try: card = pd.DataFrame(cards, columns = ["adid", "cardName", "cardBenefit", "annualFee"]) rewards=[] driver = webdriver.Chrome(service= Service(ChromeDriverManager().install())) for i in card['adid']: sub_url = f'https://card-search.naver.com/item?cardAdId={i}' driver.get(sub_url) time.sleep(0.4) print(i) details_path='//button[@class="benefit"]' detail_reward = driver.find_elements(By.XPATH, details_path) detail_rewards = [detail_reward[i].text for i in range(0,len(detail_reward))] reward = ','.join(detail_rewards) rewards.append(reward) except Exception as e: print("get rewards finished")카드 정보 데이터 프레임
위의 과정을 거쳐서 필요한 데이터를 모아 아래와 같은 데이터프레임이 만들어진 것을 확인할 수 있습니다.

데이터 프레임 export(csv파일)
필요할 때 파일만 읽어서 작업하기위해 csv파일로 export하여 네이버 신용카드 정보 크롤링 작업은 1차로 마무리합니다. 추가로 사용 종료한 selenium driver도 종료 시켜줍니다.
card['cardRewards'] = rewards card.to_csv('card_df_250323.csv') print("export finished") driver.quit()Comment
웹은 어렵고 크롤러도 어렵고..사실 더 효율적인 방법이 있을 것 같은데 지식 짧음 이슈로 말도 안되는 코드 작업이 된 것 같아서 조금 민망하긴합니다. 이러고 끝내지 않고 다른 과정으로 시도를 해볼 예정이고 더 나은 코드로 2차 작업에 대한 기록을 남길 수 있도록 해보려합니다🥲
'데이터' 카테고리의 다른 글
점점 사라지는 봄, 정말 짧아지고 있는걸까? (0) 2025.04.26 데이터 웨어하우스 알아가기 #2. 모델링 편(Star Schema, Snowflake Schema) (1) 2025.03.02 여행 갈 수 있을까..? ARIMA 모형과 함께하는 유로 환율 예측(2) (1) 2025.02.16 여행 갈 수 있을까..? ARIMA 모형과 함께하는 유로 환율 예측(1) - 전처리 (3) 2025.02.02 데이터 웨어하우스 알아가기 #1. DW(Data Warehouse)란? (1) 2025.01.18