-
[스파크 완벽 가이드 읽기]구조적API 개요기술 도서 읽기 2024. 2. 18. 10:51
안녕하세요 둔:둔입니다.
이제 '스파크 완벽 가이드(Spark The definitive Guide)' 읽기 PART2.구조적API: DataFrame, SQL, Dataset 부분을 보고 있습니다.
내용이 많고 이해가 필요한 부분이있어 이제는 Chapter 단위로 끊어보려고합니다.
구조적 API 란?
- 데이터 흐름을 정의하는 기본 추상화 개념
- 배치(Batch)와 스트리밍(Streaming) 처리에서 사용 가능하다
- 3가지 분산 컬렉션 API
- Dataset
- DataFrame
- SQL 테이블과 뷰
DataFrame 과 Dataset
- 잘 정의된 로우와 컬럼을 가지는 분산 테이블 형태의 컬렉션
- 각 컬럼은 다른 컬럼과 동일한 수의 로우를 가져야합니다(값이 없는 경우는 null 표시)
- 컬렉션의 모든 로우는 같은 데이터 타입 정보를 가지고 있어야 합니다(어찌보면 당연..)
- Dataset: 타입형
- 결과를 생성하기 위해 어떤 데이터에 어떤 연산을 적용해야하는지 정의하는 지연연산의 실행 계획 / 불변성
- 스키마 명시된 데이터 타입 일치 여부를 컴파일 타입에서 확인
- JVM기반의 언어 스칼라와 자바에서만 지원 / 케이스클래스(case class) 혹은 자바 빈(JavaBean)을 사용해서 데이터 타입 정의
- DataFrame: 비타입형(부정확할 수 있는 표현)
- 액션을 호출하면 스파크는 트랜스포메이션을 실제로 실행하고 결과를 반화
- 스키마에 명시된 데이터 타입 일치 여부를 런타임에서 확인
- Row 타입으로 구성된 Dataset -> 자체 데이터 포맷을 사용하기에 효율적 연산이 가능
핵심용어
- 스키마: DataFrame의 컬럼명과 데이터 타입을 정의 / 데이터소스에서 얻거나(schema-on-read) 직접 정의 가능
- 컬럼
- 단순 데이터 타입: 정수형, 문자열 등
- 복합 데이터 타입: 배열, 맵 등
- null 값
- 로우: 데이터 레코드 '연산에 최적화된 인메모리 포맷'의 내부적인 표현 방식 / DataFrame의 레코드는 Row 타입으로 구성된다.
스파크 데이터 타입
스파크는 여러 내부 데이터 타입을 가지고 있습니다. 다양한 프로그래밍 언어의 데이터 타입이 스파크의 어떤 데이터 타입과 매핑되는지 확인 필요(공식문서 참조)
구조적 API의 실행 과정
1. DataFrame / Dataset / SQL을 이용해 코드를 작성
2. 정상적인 코드라면 스파크가 논리적 실행 계획으로 변환
3. 스파크는 논리적 실행 계획을 물리적 실행 계획으로 변환하며 그 과정에서 추가적인 최적화 가능 여부 확인
4. 스파크는 크러스터에서 물리적 실행 계획(RDD 처리)을 실행

실행할 코드를 작성하면 작성된 스파크 코드는 콘솔 / spark-submit 셸 스크립트로 실행됩니다. 카탈리스트 옵티마이저(Catalyst Optimizer)가 이 코드를 넘겨받아 실제 실행 계획을 생성, 최종적으로 스파크는 코드를 실행한 후 결과를 반환하게 됩니다.
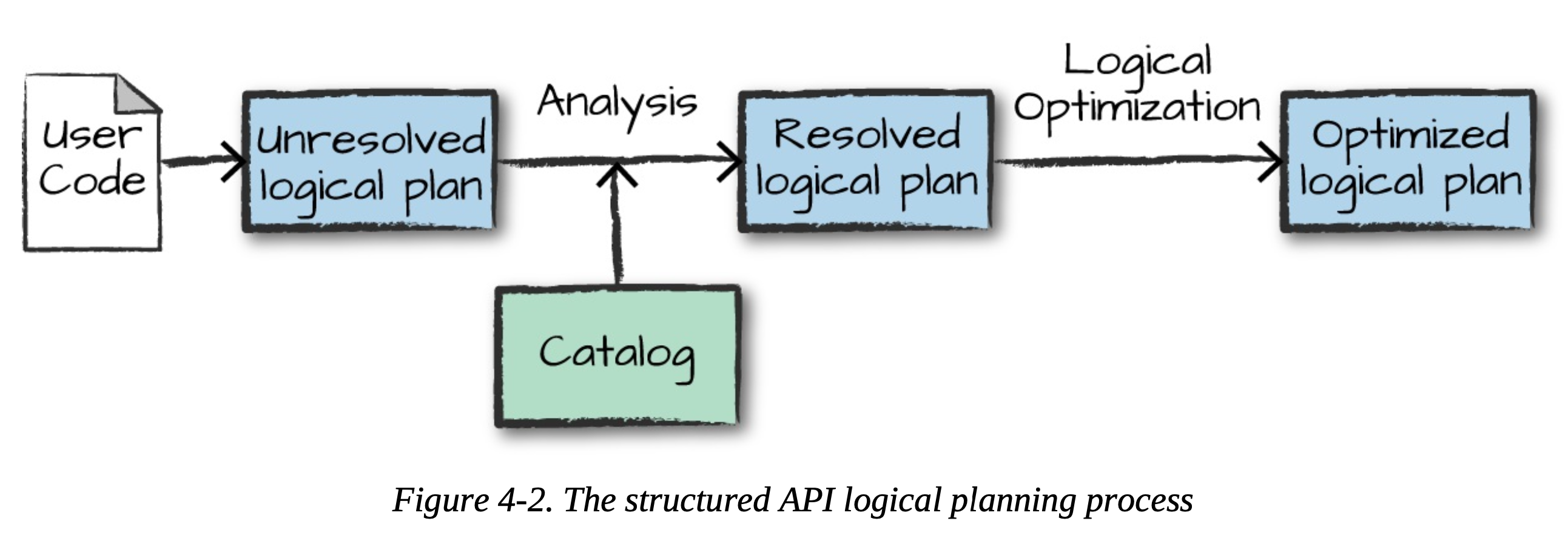
논리적 실행 계획
- 추상적 트랜스포메이션만 표현하며, 드라이버나 익스큐터의 정보는 고려하지않는 단계
- 검증 전 논리적 실행 계획(unresolved logical plan): 코드의 유효성, 테이블이나 컬럼 존재 여부만을 판단하는 과정으로 아직 실행 계획 검증하지 않은 상태
- 스파크 분석기(analyzer)가 컬럼과 테이블을 검정하기 위해 카탈로그, 모든 테이블의 저장소, DataFrame 정보를 활용
(필요한 테이블, 컬럼이 카탈로그에 없다면 검증 전 놀리적 실행 계획은 만들어지지 않는다) - 테이블, 컬럼에 대한 검증 결과는 카탈리스트 옵티마이저로 전달
- 카탈리스트 옵티마이저: 조건절 푸시 다운(predicate pushing down)이나 선택절 구문을 이용해 논리적 실행 계획을 최적화하는 규칙의 모음 / 필요한 경우 확장형 패키지 만들수도 있음!
물리적 실행 계획(=스파크 실행 계획)
- 논리적 실행 계획을 클러스터 환경에서 실행하는 방법을 정의
- 여러 물리적 실행 전략을 생성하고 비용 모델을 이용하여 비교 후 최적의 전략 선택
- 비용 비교 예시: 테이블의 크기, 파티션 수 등 물리적 속성을 고려하여 조인 연산 수행에 필요한 비용을 계산하고 비교
- 물리적 실행계획은 일련의 RDD 트랜스포메이션으로 변환
- 스파크는 DF, Dataset, SQL로 정의된 쿼리를 RDD 트랜스포메이션으로 컴파일
- 스파크를 '컴파일러'로 지칭하기도..
실행
- 물리적 실행 계획을 선정한 다음 저수준 프로그래밍 인터페이스인 RDD를 대상으로 모든 코드를 실행
- 런타임에 전체 태스크(task)나 스테이지(stage)를 제거할 수 있는 자바 바이트 코드를 생성해 추가적인 최적화 수행
- 처리결과를 사용자에 반환
*개인 코멘트
구조적 API 실행 과정을 보면서 SQL의 실행계획 과정도 함께 떠올리기도 했습니다. DataFrame을 사용 시 스파크의 최적화된 내부 포맷을 사용할 수 있기에 어떤 언어 API이더라도 동일 효과와 효율성을 얻을 수 있다는 점을 잘 생각해두려합니다.
아직도 어려운 글쓰기..! 한 단계 더 나아간 내용을 쓸 수 있을 때까지 열심히 하는 걸로..
'기술 도서 읽기' 카테고리의 다른 글
[책 읽기]그림으로 이해하는 가상화와 컨테이너 #1. 가상화 기초지식 (1) 2025.03.16 [스파크 완벽 가이드 읽기]PART1. 빅데이터와 스파크 간단히 살펴보기 (3) 2023.12.24